Choice of $D$
One of the most important modeling properties is the underlying divergence or distance between $P_R$ and $P_G$ thats being minimized. Often times this attribute is simply left as the consequence of other decisions. For instance maximum likelihood learning is asymptotically equivalent to minimizing $KL(P_r, P_{\theta})$ when both distributions admit densities and are absolutely continuous with respect to some measure $\mu$. (Arovsky et al 2017)
An interesting question is: does it makes sense take a reverse approach? Begin by thinking of which underlying $D$ should be minimized then make other decisions accordingly.
To begin answering this question let's review some of the different families of divergences and outline some modeling approaches that relate to those families.
First note that to qualify as a true distance a measure $\textit{d}$ must fulfill the following: (Bottou et al 2017)
- $d(x, x)=0$
- $x \neq y \implies d(x,y)>0$
- $d(x,y) = d(y,x)$
- $d(x, y) \leq d(x, z) + d(z, y)$
When a measure $d$ fails to fulfill (3) or (4), its called a divergence. To encompass both divergences and distances we will refer to $D$ from our original definition of generative modeling for convenience.
There are many families of $D$ and many more modeling procedures that utilize them. We will go through some well studied families of divergences/distributions and give choice examples of modeling approaches that minimize divergences/distances in those families.
f-divergences
A well studied class of divergences are the $f-divergences$.
Let $P$ and $Q$ be two probability distributions over a space $\Omega$ such that $P$ is absolutely continuous with respect to $Q$. Then, for a convex function $f$ such that $f(1)=0$ the f-divergence of $P$ from $Q$ is defined as: $$D_f(P || Q) = \int_{\Omega} f(\frac{dP}{dQ})dQ$$
Different choices of $f$ give us different f-divergences:
| Name | $\mathbf{\mathcal{f}(t)}$ |
| KL-divergence | $t \log t$ |
| Reverse KL-divergence | $-\log t$ |
| Alpha divergence | $ \begin{cases} \alpha \neq \pm 1 & \frac{4}{1-\alpha^2}(1-t^{\frac{(1+ \alpha)}{2}}) \\ \alpha = 1 & t \ln t \\ \alpha = -1 & -\ln t \end{cases} $ |
| Squared Hellinger | $(\sqrt{t} -1)^2$ |
| Jensen Shannon | $-(t+1)\log \frac{1+u}{2} +u \log u$ |
| Pearson $\mathcal{X}^2$ | $(u-1)^2$ |
| Total variation | $\frac{1}{2} |t-1|$ |
The most famous F-divergence is the Kl-divergence (kullback-leibler divergence) which shows up all throughout machine learning and statistics
$$KL(\mathbb{P_r}, \mathbb{P_g}) = \int \log(\frac{p_r(x)}{p_g(x)})p_r(x) d\mu(x) $$ where both distributions $\mathbb{P_r}, \mathbb{P_g}$ are absolutely continuous and admit densities $p_r, p_q$ with respect to some measure $\mu$ defined on $\mathcal{X}$. (Arjovsky et al 2017)
In the context of generative modeling it often comes up because the maximum likelihood estimation problem: $\max_{\theta \in \mathbb{R}}\sum_{i}^{m} \log P_{\theta}(x_i)$ is equivalent to $KL(P_{r}, P_{\theta})$ when the parameterized density $P_{\theta}$ corresponds to the distribution $\mathbb{P_{\theta}}$ and $P_{r}$ is the density of $\mathbb{P_r}$.
One concern that we will revisit is that if the model density $P_\theta$ doesn't actually exist then it doesn't make sense to do maximum likelihood learning. Furthermore, if the data distribution $P_r$ doesn't actually admit a density, it doesn't make sense to do density estimation at all. (Arjovsky et al 2017)
To get some intuition for the KL divergence, consider this plot of values of $\log(\frac{p(i)}{q(i)})$ evaluated on a discrete grid.
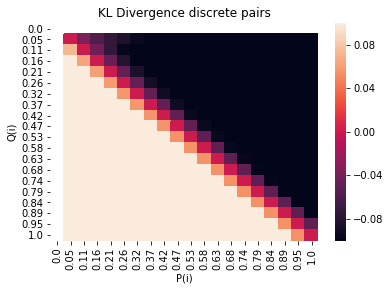
f-gan
Nowozin et al 2016 provide a general framework for doing learning by comparison using generic f-divergences. They build on earlier work by Nguyen et al. 2018 who were interested in estimating f-divergences from samples but not in the context of learning a model.
Recall that an f-divergences for two distributions $P$ and $Q$ with absolutely continuous densities $p$ and $q$ with respect to some measure $dx$ on a domain $\mathcal{X}$ is $$D_f(P || Q)\int_{\mathcal{X}}q(x)f(\frac{p(x)}{q(x)})dx$$ where $f:\mathbb{R_{+}}\to \mathbb{R}$ is a convex, lower semicontinuous function satisfying $f(1)=0$.
Nguyen et al 2018. first note that the Fenchel conjugate of $f$ is $f^*(t)=\sup_{u \in dom_f}\{ut -f(u)\}$ They then show that they can get a lower bound using that conjugate: $$D_f(P||Q) \geq \sup_{T \in \mathcal{T}}(E_{x \sim P} [T(x)] - E_{x \sim Q}[f^*(T(x))])$$ Where $\mathcal{T}$ is any arbitrary function class $T: \mathcal{X} \to \mathbb{R}$
This bound is tight when $T^*(x) = f'(\frac{p(x)}{q(x)})$, knowledge of which can provide useful guidance when choosing a $T$ in practice.
Nowozin et al 2016 move from the fixed model case to the task of estimating the parameters for a generative model $Q$ given some true distribution $P$.
Say we parameterize Q with $\theta$: $Q_{\theta}$ which takes a random vector and returns a sample and define a function $T_{\omega}$ that maps a sample to a scalar.
Then estimation can be done by finding the saddle point of $$F(\theta, \omega)=E_{x \sim P }[T_{\omega}(x)] - E_{x \sim Q_{\theta}}[f^*(T_{\omega}(x))]$$
The final piece of this procedure is respecting the domain of $f^*$, which is done by limiting the range of $T_{\omega}$ by using $T_{\omega}(x)=g_{f}(V_{\omega}(x))$ where $g_f: \mathbb{R} \to dom_{f^*}$ is an activation function and $V_{\omega}$ is any function that maps $\mathcal{X} \to \mathbb{R}$. Now they can give a different suggested $g$ for every f-divergence to make sure $\text{dom}_{f^*}$ is respected.
Plugging in $V_{\omega}$ gives the new objective $F(\theta, \omega)= E_{x\sim P} [g_{f}(V_{\omega}(x)) + E_{x\sim Q_{\theta}}[-f^*(g_f(V_{\omega}(x)))]$
The authors give values for $g_f$ and $f^*$ for all the f-divergences.
Integral Probability Metrics
As we alluded to in an earlier section, another well studied family of divergences/distances are the Integral Probability Metrics. Since they have a natural connection to learning by comparison they are frequently used precisely in that context.
Given a real valued, bounded and measurable set of functions $\mathcal{F}$ on $M$: $$ \gamma_{\mathcal{F}}(P, Q) = \sup_{f \in \mathcal{F}}|\int_{M} f dP - \int_M f dQ| $$
Different choices for the function class $\mathcal{F}$ give us different IPMs as shown in Sriperumbudur et al 2009
Given a metric space $(M,\rho)$ with $\mathcal{A}$ being a Borel sigma algebra induced by metric topology. let $\mathcal{P}$ be the set of all Borel probability measures on $\mathcal{A}$
| Name | Choice of $\mathcal{F}$ |
| Dudley metric |
$\mathcal{F} = \{f : ||f||_{BL} \leq 1\}$ Where: $||f||_{BL} := ||f||_{\infty} + ||f||_L$ $||f||_{\infty}:= \sup\{|f(x)| : x \in M\}$ $||f||_L:=\sup\{|f(x) -f(y)|\rho(x,y) :x \neq y \in M\}$ |
| Maximum mean discrepancy |
$\mathcal{F} = \{f: ||f||_{\mathcal{H}} \leq 1 \}$ $H$ is a reproducing kernel Hilbert space with $k$ as its reproducing kernel. |
| Kantorovich metric | $\mathcal{F}=\{f: ||f||_L \leq 1 \}$ |
| Total variation distance | $\mathcal{F} =\{f: ||f||_\infty \leq 1\}$ |
| Kolmogorov distance | $\mathcal{F}=\{\mathcal{1}_{(\infty, t]}, t \in \mathbb{R}^d\}$ |
The Kantorovich metric has a dual form (Sriperumbudur 2009) that is gaining increasing visibility within machine learning called the Wasserstein distance/metric: $W(\mathbb{P}, \mathbb{Q})$ (Sriperumbudur et al)
The Wasserstein-1 distance is defined as $W(\mathbb{P_r}, \mathbb{P_g})= \inf_{\eta \in \prod(\mathbb{P_r}, \mathbb{P_g})} \mathbb{E}_{x,y} \sim \eta[||x-y||]$
Wasserstein GAN
In Arjovsky et al 2017 the authors develop a method for deep generative modeling through comparison style learning using the Wasserstein distance. They start by proving that it makes sense to use the Wasserstein distance in the context of neural networks and gradient descent.
Take a distribution $\mathbb{P_r}$ over some $\mathcal{X}$. Let $Z$ be a random variable over $\mathcal{Z}$, let $g:\mathcal{Z} \text{ X } \mathbb{R^d} \to \mathcal{X}$ be a function parameterized by $\theta$ ($g_{\theta}$). Finally lets call the distribution of $g_{\theta}(Z)$ $\mathbb{P}_{\theta}$ Arjovsky et al 2017 show that $W(\mathbb{P}_r, \mathbb{P}_{\theta})$ is continuous in $\theta$ if $g$ is continuous in $\theta$. They also show that if $g$ is locally Lipshitz then $W(\mathbb{P_r}, \mathbb{P_{\theta}})$ is as well. Finally if $g_{\theta}$ is a neural network and there's a prior over $p(z)$ such that $\mathbb{E}_{z \sim p(z)}[|z|]< \infty$ then all of the above claims are still true.
We can now use the comparison based learning approach to optimize the Wasserstein loss, but for the fact that the infimum is not computationally tractable. Luckily the Wasserstein distance can be re-written as $$ W(\mathbb{P_r}, \mathbb{P_{\theta}})=\sup_{|f|_{L \leq 1}} \mathbb{E}_{x \sim \mathbb{P_r}}[f(x)]-\mathbb{E}_{x \sim \mathbb{\theta}}[f(x)]$$ where we take take a supremum over 1-Lipschitz functions instead.
If we relax this to K Lipschitz functions $||f|_{L}|\leq K$ then the authors of the W-Gan paper (Arjovsky et al 2017) suggest that the following makes sense: $$\max_{w \in W}\mathbb{E}_{x \sim \mathbb{P}_r}[f_{w}(x)]- \mathbb{E}_{z \sim p(z)}[f_w(g_{\theta}(z))]$$ The authors prove that if we can find $w \in W$ for which the supremum in the original formulation is achieved, then you we would get $W(\mathbb{P}_r, \mathbb{P_{\theta}})$ up to some constant K.
Learning is then done by comparison with the small twist that we clamp the weights $W$ such that they lie in a fixed box so that$f_w$ is guaranteed to be K-Lipschitz
Arjovsky et al. point out a lot of useful properties of the Wasserstein distance not shared by f-divergences (at least KL, Jensen-Shannon, and total variation). They argue that if one wants to use an f-divergence, the data distribution $P_r$ and the model distribution $P_{\theta}$ must both be absolutely continuous with respect to some measure $\mu$ and admit densities. If this is not the case, for instance when the data distribution lies on a low dimensional manifold, or the model density does not exist, then an f-divergence doesn't make sense. They also point out that this is often true in cases like the space of natural images. This issue is usually solved in practice by injecting noise into the model which Arjovsky et al. note will necessarily affect the sharpness of the final samples.
Another claim made by Arjovsky et al. is that the Wasserstein distance provides stronger guarantees for convergence when doing estimation by comparison (GAN) style learning than the jensen-shannon, KL or total variation. They show via an example, and through a proof, that the Wasserstein distance induces a weaker topology than KL, JS or TV divergences, and thus provide more favorable convergence properties.
MMD GAN
The maximum mean discrepancy has also been used in conjunction with comparison style learning as in Li et al. 2017
Li et al Assume data $\{x_i\}_{i=1}^n$ where $x_i \in \mathcal{X}$ and $x_i \sim \mathbb{P_{\mathcal{X}}}$ they then follow the implicit modeling approach of a generator $g_{\theta}$ which transforms samples $z \sim \mathbb{P_z}, z \in \mathcal{Z}$ into $g_\theta(z) \sim \mathcal{P_{\theta}}$ They then compare $\mathbb{P}_{\theta}$ and $\mathbb{P_{\mathcal{X}}}$ using a two sample test via a kernel maximum mean discrepancy. Given two distributions $\mathbb{P}, \mathbb{Q}$ and a kernel k, the squared MMD distance is $$M_k(\mathbb{P}, \mathbb{Q})= || \mu_{\mathbb{P}} - \mu_{\mathbb{Q}}||_{H}^2$$ This is equivalent to $$2 \mathbb{E}_{\mathbb{P}, \mathbb{Q}}[k(x,y)] + \mathbb{E_{\mathbb{Q}}}[k(y, y')] $$ If k is a characteristic kernel then we know $M_k(\mathbb{P}, \mathbb{Q})=0 \iff \mathbb{P} = \mathbb{Q}$ This could lead to the following training procedure for $g_{\theta}$: $$\min_{\theta} \max_{k \in \mathcal{K}} M_k(\mathbb{P_{\mathcal{X}}}, \mathbb{P_{\theta}})$$ Its intractable to optimize over all characteristic kernels, but consider the following: if $f$ is an injective function and k is characteristic then the function $\hat{k}=k \circ f$ where $\hat{k}(x, x') = k(f(x), f(x'))$ is also characteristic. This means we can replace the search over all ks with a search over a family of injective functions parametrized by $\phi $ and some fixed k: $$\min_{\theta}\max_{\phi} M_{k \circ f_{\phi}}(\mathbb{P_{\mathcal{X}}}, \mathbb{P_{\theta}})$$ To approximate this the authors use neural networks to approximate $g_{\theta}$ and $f_{\phi}$ Since the gradient $\nabla_{\theta}(\max_{\phi}f_{\phi} \circ g_{\theta})$ has to be bounded, they clip $\phi$. To ensure $f_{\phi}$ is injective they use the the fact that for an injective function f there must be an inverse $f^{-1}$ such that $f^-1(f(x))=x, \forall x \in \mathcal{X}$. Also: $f^-1{f(g(z))}=g(z) \forall z \in \mathcal{Z}$. They choose to approximate this with an autoencoder. So the parameters of the discriminator $f_{\phi}$ are seperated into $\phi={\phi_e, \phi_d}$ for the encoder and decoder respectively. The relaxed objective is then : $$\min_{\theta} \max_{\phi} M_{f_{\phi_e}}(\mathbb{P}(\mathcal{X}), \mathbb{P}(g_{\theta}(\mathcal{Z}))) - \lambda \mathbb{E_{y \in \mathcal{X} \bigcup g(\mathcal{Z})}}||y-f_{\phi_d} (f_{\phi_e}(y))||^2$$ This is optimized in the alternating style of comparison based (gan) learning discussed earlier.
Cramer GAN
A final example we will look at is with the Cramer distance as introduced by Bellemare et al. 2017 .
The Cramer distance for two distributions $\mathbb{P}, \mathbb{Q}$ over $\mathbb{R}$ with cumulative distribution functions $F_P, F_Q$ respectively is $$l^2_2(P,Q):= \int_{-\infty}^{\infty} (F_P(x) - F_Q(x))^2 dx$$ The square root of which is a proper metric: $$l_p(P, Q):= (\int_{-\infty}^{\infty}|F_P(x) - F_Q(x)|^p dx)^\frac{1}{p} $$
This is equivalent to the Wasserstein metric when p=1.
The Integral Probability Metric form of the Cramer distance is the dual form: $$l_p(P,Q)= \sup_{f \in \mathbb{F_q}} |\mathbb{E_{x \sim P}} f(x) - \mathbb{E_{x \sim Q}}f(x)| $$ where $\mathbb{F_q := \{f:f \text{ is absolutely continuous}, || \frac{df}{dx}||} \leq 1\}$ and $p^{-1} + q^{-1} =1$
To extend to the multivariate case they use the energy distance (Rizzo et al 2016) : $$\mathcal{E}(P,Q):= \mathcal(E)(X,Y):= 2\mathbb{E}||X-Y||_2 - \mathbb{E}||X-X'||_2 - \mathbb{E}||Y -Y'||_2$$ where P, Q are distributions over $\mathbb{R^d}$ and $X, X'$ and $Y, Y'$ are independent random variables distributed according to P and Q respectively. The above is equal to $$f^*(x):=\mathbb{E}||x- Y'||_2 - \mathbb{E}||x - X'||_2$$ thus $$\mathcal{E} = \mathbb{E}f^*(X)- \mathbb{E}f^*(Y)$$
Now to use comparison style training we define the two losses for the generator and discriminator and follow the following procedure:
First sample the following: $$x_r \sim P$$ $$x_g, x_g \sim Q$$ $$\epsilon \sim \text{Uniform}(0,1)$$ Let $$\hat{x} = \epsilon x_r + (1- \epsilon) x_g$$ Take a discriminator (or critic) $$f(x) = ||h(x) - h(x^{'}_g)||_2 - ||h(x)||_2$$ The generator loss is then: $$L_g = ||h(x_r) -h(x_g) ||_2 + ||h(x_r)-h(x'_g)||_2- ||h(x_g)-h(x'_g)||_2$$ A surrogate generator loss is provided as: $$L_{surrogate}=f(x_r)-f(x_g)$$ Then the discriminator/critic loss is $$L_{critic}= - L_{surrogate}+ \lambda(||\nabla_{\hat{x}} f(\hat{x})||_2 -1)^2$$
To motivate using the Cramer distance Bellemare et al 2017 give 3 ideal desiderata that they claim any divergence should obey and show that the Cramer distance satisfies them while the KL and Wasserstein do not.
- Scale sensitive For two random variable X, Y with distributions P, Q and divergence d $d(X,Y):=d(P,Q)$, d is scale sensitive of order $\beta$ if there exists a $\beta>0$ such that for all X, Y and a real value $c>0$ $$d(cX, cY) \leq |c|^{\beta}d(X, Y)$$
- Sum invariant: A divergence $d$ is sum invariant if whenever A is independent from X, Y $$d(A + X, A + Y) \leq d(X,Y)$$
- Unbiased sample gradients: Given $X_m := X_1 .. X_m $ drawn from a distribution P, the empirical distribution $\hat{P_m}:= \frac{1}{m}\sum_{i=1}^m \delta_X$ and a distribution $Q_{\theta}$ $$\mathbb{E_{x_m \sim P}} \nabla_{\theta}l^2_2(\hat{P_m}, Q_{\theta}) = \nabla_{\theta}l^2_2(P, Q_{\theta})$$
Bregman divergences
For two continuous distributions $\mathbb{P}$, $\mathbb{Q}$ and a strictly convex function $\phi(x):\mathbb{R} \to \mathbb{R}$ $$D_{\phi}(\mathbb{P}, \mathbb{Q}) = \int[ \phi(p(x))-\phi(q(x)) - \phi'(q(x))(p(x) - q(x))]d\mu(x)]$$ where $p(x)$ and $q(x)$ are the probability density functions of $\mathbb{P}$ and $\mathbb{Q}$ respectively and $\mu$ is the base measure.
Different choices of $\mathbb{\phi}$ lead to different Bregman divergences as shown in (Sugiyama et al 2011)
| Name | Choice of $\mathbb{\phi}$ |
| $L^2$ loss | $\phi(x)= ||x||_{2}^2$ |
| Itakura-Saito divergence | $\phi(x) = - \log(x)$ |
| KL divergence | $\phi(x) = \sum_{i=1}^d x_i \log x_i$ |
| Mahalonobis distance | $\phi(x) = x^T A x$ where A is positive definite |
Experiments
The divergence that ends up being minimized has a big impact on the final learned model. Extending experiments done in Theis et al. 2016 we show here plots of an isotropic Gaussian trained to fit data generated from a random mixture of Gaussians using various choices of $D$ in the learning by comparison style. Though things are assuredly different in high dimensions, we can start seeing the kinds of trade-offs being made by visualizing this simple example.
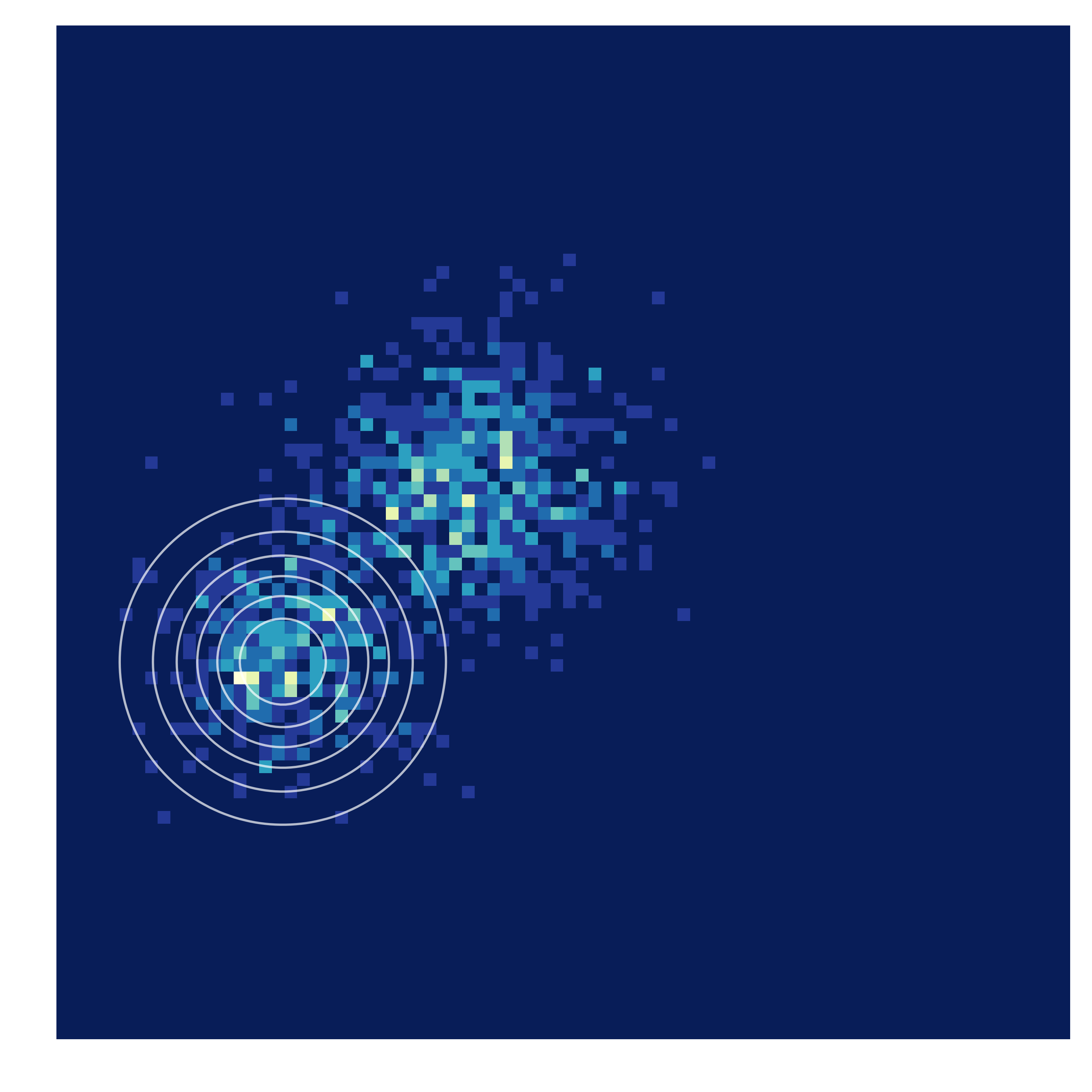






Conclusion
We tried to organize the landscape of deep generative models by their modeling choices, the principle of learning employed, and the underlying divergence that ends up being minimized. We attempted to delineate some broad categories which we described in more detail, but necessarily omitted many variations and alternatives. We looked at different families of distances and divergences between distributions and provided examples of how different popular models minimize those divergences.
References
Nowozin, S., Cseke, B., & Tomioka, R. (2016). f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization.
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein GAN.
Arjovsky, M., & Bottou, L. (2017). Towards Principled Methods for Training Generative Adversarial Networks.
Bellemare, M. G., Danihelka, I., Dabney, W., Mohamed, S., Lakshminarayanan, B., Hoyer, S., & Munos, R. (2017). The Cramer Distance as a Solution to Biased Wasserstein Gradients.
Rezende, D. J., Mohamed, S., & Wierstra, D. (2014). Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014 (pp. 1278–1286). Retrieved from http://jmlr.org/proceedings/papers/v32/rezende14.html
Sriperumbudur, B. K., Fukumizu, K., Gretton, A., Schölkopf, B., & Lanckriet, G. R. G. (2009). On integral probability metrics, φ-divergences and binary classification.
Li, C.-L., Chang, W.-C., Cheng, Y., Yang, Y., & Póczos, B. (2017). MMD GAN: Towards Deeper Understanding of Moment Matching Network.
Sugiyama, M., Suzuki, T., & Kanamori, T. (2011). Density-ratio matching under the Bregman divergence: a unified framework of density-ratio estimation. SpringerLink. Springer Japan. Retrieved from https://link.springer.com/article/10.1007/s10463-011-0343-8
Theis, L., van den Oord, A., & Bethge, M. (2016). A note on the evaluation of generative models. In International Conference on Learning Representations. Retrieved from http://arxiv.org/abs/1511.01844
Bottou, L., Arjovsky, M., Lopez-Paz, D., & Oquab, M. (2017). Geometrical Insights for Implicit Generative Modeling.
Bellemare, M. G., Danihelka, I., Dabney, W., Mohamed, S., Lakshminarayanan, B., Hoyer, S., & Munos, R. (2017). The Cramer Distance as a Solution to Biased Wasserstein Gradients.
Nguyen, X. L., Wainwright, M. J., & Jordan, M. I. (2008). Estimating divergence functionals and the likelihood ratio by penalized convex risk minimization. In J. C. Platt, D. Koller, Y. Singer, & S. T. Roweis (Eds.), Advances in Neural Information Processing Systems 20 (pp. 1089–1096). Curran Associates, Inc.
Rizzo, M. L., & Szekely, G. J. (2016). Energy Distance. WIREs Comput. Stat., 8(1), 27–38. https://doi.org/10.1002/wics.1375